Login to continue
Don't have an account? Register here.
 Continue with Google
Continue with Google
 Continue with LinkedIn
Continue with LinkedIn
Continue With Email
By signing in, I agree to the
Privacy Policy and
Terms Of Service.
Change Password









Robots.txt Generator
3.6
Add Directive

Analysis
Generated Robots.txtInstruct search engines robots on how to crawl. LEARN MORE
Get generated code:
1.
Enter the details
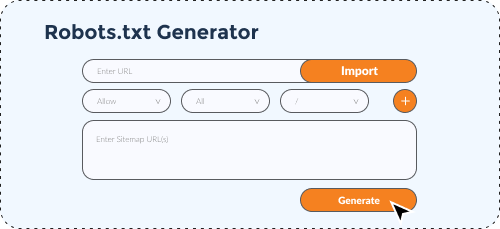
The usage of Robots.txt Generator Tool is simple enough. Here are the steps to be followed to create an effective Robots.txt file.
1. Provide the URL of your website.
2. Select whether you would like to allow or disallow certain sets of URLs.
3. Select the Search Engine bots you would like to allow or disallow.
4. Provide the URL of the specific page/folder that you would like to block.
5. You can use the (+) sign and add more number of entries in a similar way.
6. Add the URL destination of the sitemap.
Click on the button ‘Generate Robots.txt’.
*Please note that while you mention the URL you would like to block, provide only the suffix part of the URL after the domain name and the (/) sign.
2.
Result
You may simply copy the code and place it to the Robots.txt file of your website.

Tool FAQ
What’s the next step after the Robots.txt file is generated?
Once the Robots.txt file is generated, submit it at the root directory of your website.
Why do we need to provide sitemap information in Robots.txt file?
As iterated, Robots.txt file is the first file visited by Search Engine Robots before it crawls the entire website. Hence, it is important to provide the URL destination of the sitemap so that Search Engine spiders can access it quickly.
What is Robots.txt file?
Robots.txt is a text file which is created with the purpose of indicating to search engine spiders the pages that are being blocked from the crawling process.
How to implement Robots.txt?
A Robots.txt file is created in a text file with disallow command, thereby instructing the search engine spiders about the pages that shouldn't be crawled. The same Robots.txt file is placed in the root directory of the website.
How to remove Robots.txt file from website?
The Robots.txt file is located at the root directory of the website. To remove it, one would only need to take down the file from there.
What should I put in Robots.txt?
In the Robots.txt file, one should mention the pages that's to be blocked from crawling by search engine robots.
The disallow command helps in blocking pages/folders from getting crawled.
Allow command is occasionally used in case is a certain page(s) are to be still crawled from a blocked folder.
The location of XML sitemap is too mentioned.
The disallow command helps in blocking pages/folders from getting crawled.
Allow command is occasionally used in case is a certain page(s) are to be still crawled from a blocked folder.
The location of XML sitemap is too mentioned.
Is Robots.txt necessary?
Robots.txt is absolutely necessary for search engines - it is the first file accessed by the search engine robots to ascertain the pages that it should or should not crawl.
Where can I find Robots.txt?
The Robots.txt can be found at the root directory of the website - you can access the file by typing robots.txt as suffix/extension after the domain.For example, if your domain is abc.com, the robots.txt file can be accessed by typing in www.abc.com/robots.txt.
Can Google crawl without Robots.txt?
Yes, Google can still access your website even if you don't have a Robots.txt file at the root directory.
However still, it is recommended to have Robots.txt file as it is necessary for the search engine spiders to understand the pages that are blocked from crawling. Also, it provides sitemap information to the search engine spiders that facilitate indexation.
However still, it is recommended to have Robots.txt file as it is necessary for the search engine spiders to understand the pages that are blocked from crawling. Also, it provides sitemap information to the search engine spiders that facilitate indexation.
How to check if Robots.txt is working?
The only way to ascertain whether the Robots.txt file is working or not, is to directly check on the search engine by tying in the website URL. If the site appears in the search results, the robots.txt is not working or Google has disregarded the Robots.txt file.
You can then check if there are any technical error in the process of creating Robots.txt.
In certain situations, the search engine can disregard the Robots.txt file and still crawl the blocked pages. To ensure that a page is indeed blocked, one can make use of the Robots metatag.
You can then check if there are any technical error in the process of creating Robots.txt.
In certain situations, the search engine can disregard the Robots.txt file and still crawl the blocked pages. To ensure that a page is indeed blocked, one can make use of the Robots metatag.
Login to continue
Don't have an account? Register here.
LOCATIONS
Global Headquarters
3 Independence Way, Suite #203,
Princeton, NJ 08540
Call: 609.356.5112
Asia Pacific Office
601, Jain Sadhguru Capital Park,
Image Garden Road,
Madhapur, Hyderabad-500081,
Telangana, India




Ask The Expert